Rollo 5050 Exterior – Verde
Rollo 5050 Exterior – Verde  Rollo 5050 Exterior – Amarillo
Rollo 5050 Exterior – Amarillo  Rollo 3528 Exterior – Rojo
Rollo 3528 Exterior – Rojo  Mini Neon Flex Verde
Mini Neon Flex Verde  Spot Dicroica Redondo Movil Blanco
Spot Dicroica Redondo Movil Blanco  Rollo 3528 Exterior – Blanco Frío
Rollo 3528 Exterior – Blanco Frío 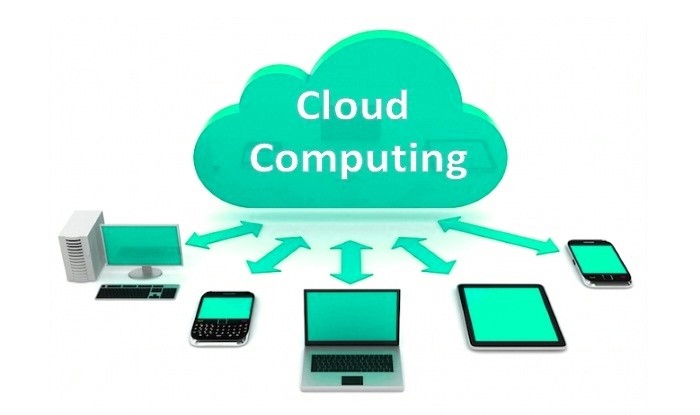
Introducción
Cloud computing es el desarrollo y la utilización de capacidad de procesamiento computacional basado en Internet (la “nube”). El concepto es un cambio de paradigma, a través del cual los usuarios ya no necesitan contar con conocimientos, experiencia o control sobre la infraestructura tecnológica que se encuentra “en la nube”, la misma que soporta sus actividades. Este concepto involucra típicamente la provisión de recursos fácilmente escalables y casi siempre virtualizados, tratados como servicios sobre Internet.
El término “nube” (cloud en inglés) es usado como una metáfora para el Internet, basado en como el Internet es representado en los diagramas de redes computacionales y como abstracción de la infraestructura subyacente que el misma oculta. Los proveedores de cloudcomputing proveen aplicaciones en línea de negocio, las mismas que se pueden acceder desde exploradores de internet (Firefox, IE, Opera, Chrome, Safari, etc), mientras el software y los datos son almacenados en los servidores.
Estas aplicaciones están ampliamente divididas en las siguientes categorías: Software como Servicio (Software as a Service – SaaS), Utility Computing, Web Services, Plataformas como Servicio (Platform as a Service – PaaS), Proveedores de Servicios Administrados (ManagedServiceProviders – MSP), Servicio de Comercio (Service Commerce) e Integración de Internet (Internet Integration).
El nombre de “cloudcomputing” fue inspirado por el símbolo de la nube que usualmente representa a la Internet en diagramas de flujo y de redes.
Historia
La computación en nube ha recorrido un largo camino desde que fue marcada por primera vez como una perspectiva de futuro por parte de algunos investigadores. La historia inicial de la computación en nube nos lleva a finales del siglo veinte, cuando la prestación de servicios de computación comenzó. Sin embargo el concepto se remonta a J.C.R. Licklider y John McCarthy.
La computación en nube ha recorrido un largo camino desde que fue marcada por primera vez como una perspectiva de futuro por parte de algunos investigadores. La historia inicial de la computación en nube nos lleva a finales del siglo veinte, cuando la prestación de servicios de computación comenzó. Sin embargo el concepto se remonta a J.C.R. Licklider y John McCarthy.
El término «nube» se utiliza como una metáfora de Internet, basado en el dibujo de nubes utilizado en el pasado para representar a la red telefónica, y más tarde para representar a Internet en los diagramas de red de computadoras como una abstracción de la infraestructura subyacente que representa.
El cloudcomputing o computo en la nube es una evolución natural de la adopción generalizada de la virtualización, la arquitectura orientada a servicios y utilidad del cómputo. La idea básica es que los usuarios finales ya no necesitan tener conocimientos o el control sobre la infraestructura de tecnología «en la nube» que los apoya.
El concepto básico del cloudcomputingo computación en nube se le atribuye aJohn McCarthy – responsable de introducir el término “inteligencia artificial». En 1961, durante un discurso para celebrar el centenario del MIT, fue el primero en sugerir públicamente que la tecnología de tiempo compartido (Time-Sharing) de las computadoras podría conducir a un futuro donde el poder del cómputo e incluso aplicaciones específicas podrían venderse como un servicio (tal como el agua o la electricidad). Esta idea de una computadora o utilidad de la información era muy popular en la década de 1960, incluso algunas empresas comenzaron a proporcionar recurso compartidos como oficina de servicios – donde se alquilaba tiempo y servicio de computo. El sistema de tiempo compartido proporcionaría un ambiente operacional completo, incluyendo editores de texto y entornos de desarrollo integrado para lenguajes de programación, paquetes de programas informáticos, almacenamiento de archivos, impresión masiva y de almacenamiento offline. A los usuarios se les cobraba un alquiler por el terminal, las horas de tiempo de conexión, tiempo del CPU y kilobytes mensuales de almacenamiento en disco. Sin embargo, esta popularidad se desvaneció a mediados de los 70s cuando quedó claro que el hardware, software y las tecnologías de comunicación simplemente no estaban preparados.
El concepto de una red de computadoras capaz de comunicar usuarios en distintas computadoras fue formulado por J.C.R. Licklider de Bolt, Beranek and Newman (BBN) en agosto de 1962, en una serie de notas que discutían la idea de una «Red Galáctica».
En 1996, Douglas Parkhill con su libro llamado «El desafío de la utilidad de la computadora» exploró a fondo muchas de las características actuales de la computación en nube (aprovisionamiento elástico a través de un servicio de utilidad), así como la comparación de la industria eléctrica y el uso de las formas públicas, privadas, comunitarias y gubernamentales. Pero otros investigadores afirman que las raíces de la computación en nube nos llevan hasta la década de 1950 con las observaciones de HerbGrosch. Él decía que la potencia de una computadora es proporcional al cuadrado de su precio (Ley Grosch), sin embargo la ley de Moore se encargó de desmentir esto. Algunos académicos recientemente han rehabilitado la ley de Grosch, mirando la historia de la computación en la nube, afirman que «Grosch estaba equivocado sobre el modelo del costo de la computación en nube, no se equivocaba en su suposición de que las economías eficientes y adaptables podría alcanzar su objetivo si confían en centros de datos centralizados en lugar confiar en el almacenamiento de unidades».
Las empresas de telecomunicaciones hasta la década de los 90s eran quienes ofrecían redes privadas virtuales (VPN) con una calidad de servicio semejante, pero a un costo mucho menor. Al ser capaces de equilibrar el tráfico pudieron hacer uso del ancho de banda total de la red con mayor eficacia. Incluso el símbolo de la nube se utiliza para indicar el punto de demarcación entre lo que es la responsabilidad del proveedor y lo que era la responsabilidad del usuario. Ahora la computación en nube extiende este límite para cubrir servidores, así como la infraestructura de red.
Uno de los pioneros en la computación en nube fue Salesforce.com, que en 1999 introdujo el concepto de entrega de aplicaciones empresariales a través de una sencilla página web. Amazon era el siguiente en el tren, al lanzar Amazon Web Service en 2002. Entonces llegó Google Docs en 2006, que realmente trajo el cloudcomputing a la vanguardia de la conciencia del público. 2006 también vio la introducción de Elastic Compute Cloud de Amazon (EC2) como un servicio web comercial que permitió a las empresas pequeñas y particulares alquilar equipos en los que pudieran ejecutar sus propias aplicaciones informáticas.
Esto fue seguido por una colaboración de toda la industria en 2007 entre Google, IBM y una serie de universidades de los Estados Unidos. Luego vinoEucalyptus en 2008, como la primera plataforma de código abierto compatible con el API-AWS para el despliegue de clouds privados, seguido por OpenNebula, el primer software de código abierto para la implementación de nubes privadas e híbridas. Microsoft entraría hasta el 2009 con el lanzamiento de Windows Azure. Luego en 2010 proliferaron servicios en distintas capas de servicio: Cliente, Aplicación, Plataforma, Infraestructura y Servidor. En 2011, Apple lanzó su servicio iCloud, un sistema de almacenamiento en la nube – para documentos, música, videos, fotografías, aplicaciones y calendarios – que prometía cambiar la forma en que usamos la computadora.
Comparaciones
Cloud computing puede ser confundido con:
• Gridcomputing – “una forma de computación distribuida, a través de la cual una ‘super computadora virtual’ compuesta de un grupo de computadoras que se encuentran conectados a la red libremente, trabajan en conjunto para realizar tareas muy complejas”.
• Utilitycomputing – el “empaquetado de recursos computacionales, tales como capacidad de procesamiento y almacenamiento, medido de forma similar como los servicios tradicionales, ej.: servicio de electricidad”.
• Computación autónoma – “sistemas de computación capaces de auto-administrarse”
Efectivamente, muchas implementaciones de cloudcomputing dependen de “redes computacionales” (también llamadas Grids) de características autónomas, las mismas que se facturan como servicios.
Sin embargo cloudcomputing se inclina a expanderse más alla de las redes computacionales (grids) y de los servicios. Algunas arquitecturas exitosas en la “nube” tienen muy poca infraestructura o la misma no se encuentra centralizada e incluso ni siquiera cuentan con sistemas de facturación, como ejemplo se encuentran las redes peer-to-peer como BitTorrent y Skype, e incluso computación de voluntariado como el proyecto SETI@home.
Las capas de cloudcomputing
Existen varias capas que conforman el concepto de “Cloud Computing”, sin embargo para contar con una explicación clara y sencilla, nos concentraremos en las tres capas más importantes.
Software
El software en la nube (Software as a Service – SaaS, por sus siglas en inglés) potencia el concepto de “cloudcomputing” en una arquitectura de software, eliminando frecuentemente la necesidad de instalar y ejecutar la aplicación en la computadora del usuario final, eliminando la carga del mantenimiento del software, los costos de las operación y el soporte técnico.
Plataforma
Una plataforma en la nube (Platform as a Service – PaaS, por sus siglas en inglés) entrega una plataforma computacional y/o un conjunto de soluciones como servicio, que generalmente utilizan infraestructura en la nube y soportan software o aplicaciones en la nube. Facilita la implementación de aplicaciones sin el costo y complejidad de comprar y administrar el hardware subyacente y sus capas de software.
Infraestructura
Infraestructura en la nube (Infrastructure as a service – IaaS, por sus siglas en inglés), es la entrega de infraestructura de computación como un servicio, generalmente en un entorno de virtualización de plataforma.
Tipos de nubes
• Nube pública: es una nube computacional mantenida y gestionada por terceras personas no vinculadas con la organización. En este tipo de nubes tanto los datos como los procesos de varios clientes se mezclan en los servidores, sistemas de almacenamiento y otras infraestructuras de la nube. Los usuarios finales de la nube no conocen que trabajos de otros clientes pueden estar corriendo en el mismo servidor, red, sistemas de almacenamiento, etc.7 Aplicaciones, almacenamiento y otros recursos están disponibles al público a través el proveedor de servicios que es propietario de toda la infraestructura en sus centros de datos; el acceso a los servicios solo se ofrece de manera remota, normalmente a través de Internet.
• Nubes privadas: son una buena opción para las compañías que necesitan alta protección de datos y ediciones a nivel de servicio. Las nubes privadas están en una infraestructura bajo demanda gestionada para un solo cliente que controla qué aplicaciones debe ejecutarse y dónde. Son propietarios del servidor, red, y disco y pueden decidir qué usuarios están autorizados a utilizar la infraestructura. Al administrar internamente estos servicios, las empresas tienen la ventaja de mantener la privacidad de su información y permitir unificar el acceso a las aplicaciones corporativas de sus usuarios.
• Nubes híbridas: combinan los modelos de nubes públicas y privadas. Usted es propietario de unas partes y comparte otras, aunque de una manera controlada. Las nubes híbridas ofrecen la promesa del escalado aprovisionada externamente, en-demanda, pero añaden la complejidad de determinar cómo distribuir las aplicaciones a través de estos ambientes diferentes. Las empresas pueden sentir cierta atracción por la promesa de una nube híbrida, pero esta opción, al menos inicialmente, estará probablemente reservada a aplicaciones simples sin condicionantes, que no requieran de ninguna sincronización o necesiten bases de datos complejas.
Características
• Orientado a Fabricantes de software.
• Funcionalidades para diseñar, desarrollar, desplegar, integrar servicios y obtener capacidad operacional.
• Contenedor de aplicaciones, plataforma de ejecución, API de servicios y persistencia de datos.
Beneficios
• Mantenimiento de infraestructura tecnológica
• Centro de datos/ el Colocation
• Tiempo y dinero invertido por daños de hardware
• Perdidas por caida / Off-line por fallas de Hardware
• Sostenibilidad de un centro de datos alterno
• Mantener la bodega de datos de backups
• Velocidad con que se deprecia el hardware
• Costos ocultos por Hardware subutilizados
• Sistemas de acceso y control perimetral del centro de datos
Desventajas
• La centralización de las aplicaciones y el almacenamiento de los datos origina una interdependencia de los proveedores de servicios.
• La disponibilidad de las aplicaciones está sujeta a la disponibilidad de acceso a Internet.
• Los datos «sensibles» del negocio no residen en las instalaciones de las empresas, lo que podría generar un contexto de alta vulnerabilidad para la sustracción o robo de información.
• La confiabilidad de los servicios depende de la «salud» tecnológica y financiera de los proveedores de servicios en nube. Empresas emergentes o alianzas entre empresas podrían crear un ambiente propicio para el monopolio y el crecimiento exagerado en los servicios.4
• La disponibilidad de servicios altamente especializados podría tardar meses o incluso años para que sean factibles de ser desplegados en la red.
• La madurez funcional de las aplicaciones hace que continuamente estén modificando sus interfaces, por lo cual la curva de aprendizaje en empresas de orientación no tecnológica tenga unas pendientes significativas, así como su consumo automático por aplicaciones.
• Seguridad. La información de la empresa debe recorrer diferentes nodos para llegar a su destino, cada uno de ellos (y sus canales) son un foco de inseguridad. Si se utilizan protocolos seguros, HTTPS por ejemplo, la velocidad total disminuye debido a la sobrecarga que éstos requieren.
• Escalabilidad a largo plazo. A medida que más usuarios empiecen a compartir la infraestructura de la nube, la sobrecarga en los servidores de los proveedores aumentará, si la empresa no posee un esquema de crecimiento óptimo puede llevar a degradaciones en el servicio o altos niveles de jitter.